转载自好友公众号:加贝观止医聊室
引言Introduction
NASA-TLX,全称NASA Task Load Index,NASA任务负荷指数。
我第一次看到这个词是在2022年的学术会议上,好像是专家的PPT上有这个词,但是专家翻页特别快,我就记住了NASA,回去让小伙伴们去找这个评价方法,找了很久也没找到。这两天看文献的时候,却无意中看到了这个词。
花了一上午,把这个评价方法了解了,做个笔记。
NASA-TLX, the full name is NASA Task Load Index, the NASA Task Load Index.
I first saw this term at an academic conference in 2022. It seemed to appear on an expert's PowerPoint slide, but the expert flipped through the slides so quickly that I only remembered "NASA." Afterward, I asked my teammates to look for this evaluation method, and we searched for a long time without finding it. These past couple of days, while reading literature, I unexpectedly came across this term again.
I spent the entire morning understanding this evaluation method and am now taking some notes.
01 NASA-TLX简介 NASA-TLX Introduction
起源与开发(1980年代)
NASA-TLX由NASA艾姆斯研究中心(Ames Research Center)的人类绩效小组(Human Performance Group)开发,主导研究者为Sandra G. Hart和Lowell E. Staveland。其开发历时三年(约1985–1988年),基于40多项实验室模拟实验,旨在解决航空任务中飞行员的工作负荷量化问题。1988年,Hart与Staveland发表关键论文《Development of NASA-TLX》,正式确立该工具。Origins and Development (1980s)
NASA-TLX was developed by the Human Performance Group at NASA's Ames Research Center, led by researchers Sandra G. Hart and Lowell E. Staveland. Its development spanned approximately three years (around 1985–1988) and was based on over 40 laboratory simulation experiments. Its primary aim was to address the quantification of pilot workload in aviation tasks. In 1988, Hart and Staveland published the seminal paper "Development of NASA-TLX," formally establishing the tool.
核心目标
开发初衷是解决传统主观负荷评估的局限性:1. 高个体间变异性(between-subject variability);
2. 缺乏对多维度负荷来源的诊断能力;
3. 需适应不同任务类型的负荷差异。
Core Objectives
The original intent of its development was to address the limitations of traditional subjective workload assessments, namely:
1. High between-subject variability;
2. A lack of diagnostic capability regarding the sources of multidimensional workload;
3. The need to adapt to workload differences across various task types.
应用扩展与影响力
领域扩展:从最初航空领域延伸至医疗、军事、人机交互、VR系统等。例如,用于评估远程医疗平台、军事战术训练及VR环境中的认知负荷。
学术影响力:截至2006年已被550+研究引用,至2018年谷歌学术显示3,660+相关文献,成为主观负荷评估的"黄金标准"(gold standard)。
NASA-TLX是一种多维度主观负荷评估工具,通过六个子维度综合量化任务负荷,包含权重与评分两阶段流程:
六个负荷维度
每个维度以0–100分(5分增量)评估,描述如下:
心理负担(Mental Demand) :任务所需的认知强度(如决策、计算)。
体力负担(Physical Demand) :身体活动强度(如操作设备)。
时间负担(Temporal Demand) :任务节奏的时间压力。
努力程度(Effort) :为维持任务表现所需的主观努力。
挫折程度(Frustration) :任务引发的焦虑或挫败感。
整体表现负担(Own Performance) :参与者对自身任务完成度的评价。(注意是整体表现负担,也就是分数越高,表现越差)
Application Expansion and Influence
Field Expansion: Initially developed for aviation, NASA-TLX has since expanded into fields such as healthcare, military operations, human-computer interaction, and VR systems. For example, it is used to assess the cognitive load in telemedicine platforms, military tactical training, and virtual reality environments.
Academic Influence: By 2006, it had been cited in over 550 research papers. As of 2018, Google Scholar shows more than 3,660 related publications, establishing it as the "gold standard" for subjective workload assessment.
NASA-TLX is a multidimensional subjective workload assessment tool. It comprehensively quantifies task load through six sub-dimensions, involving a two-stage process of weighting and scoring.
The Six Workload Dimensions
Each dimension is rated on a scale of 0–100 (in 5-point increments), described as follows:
* Mental Demand: The cognitive intensity required by the task (e.g., decision-making, calculation).
* Physical Demand: The intensity of physical activity involved (e.g., operating equipment).
* Temporal Demand: The time pressure felt due to the pace of the task.
* Effort: The subjective level of effort required to maintain task performance.
* Frustration: The level of anxiety or irritation experienced during the task.
* Own Performance (Perceived Performance): The participant's assessment of their own task accomplishment. (Note: A higher score in this dimension indicates worse perceived performance.)
评估流程
权重阶段:参与者通过15组两两比较(共6个维度),选择每对中"对负荷影响更大"的维度,最终生成各维度的权重(0–5分)。
目的:个性化调整维度重要性,减少个体差异。
评分阶段:任务完成后,参与者对每个维度按0–100分评分。
注意:建议立即评分以避免近因偏差。
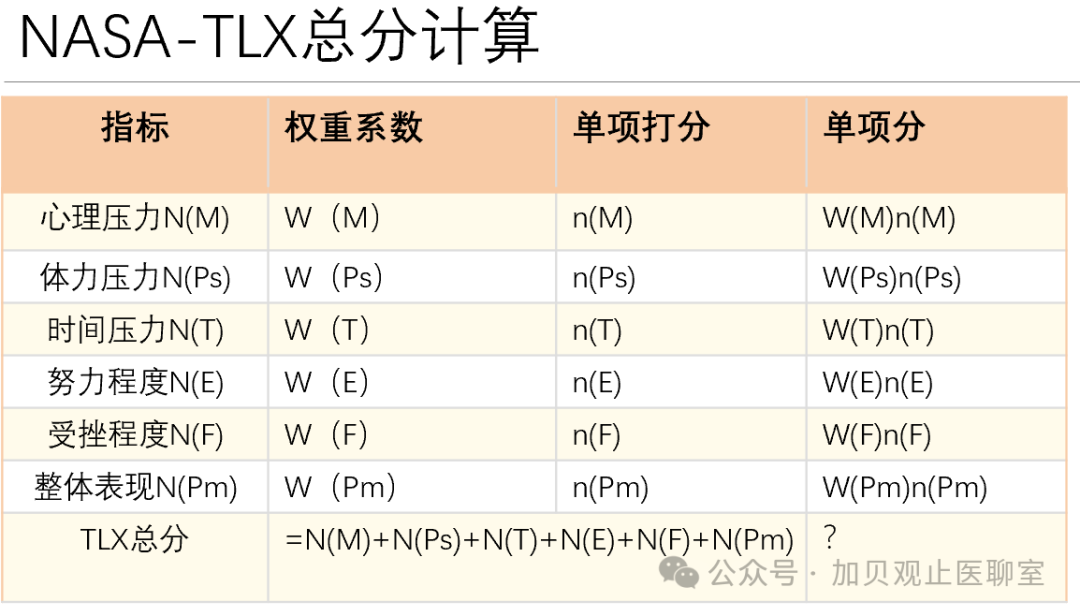
总分计算综合负荷得分 = Σ(各维度评分 × 权重) / 15。
Assessment Procedure
Weighting Phase: Participants perform a pairwise comparison across all six dimensions, selecting the dimension they consider to "contribute more to the workload" in each of the 15 pairs. This process generates a weight for each dimension (ranging from 0 to 5).
Purpose: To personalize the relative importance of each dimension, thereby reducing the impact of individual differences.
Scoring Phase: After completing the task, participants rate their perceived load on each dimension using a scale from 0 to 100.
Note: It is recommended to conduct the scoring immediately after the task to avoid recency bias.
Overall Score Calculation:
Composite Workload Score = Σ (Rating for each dimension × Its corresponding weight) / 15
02 应用举例:手术机器人
现在很多手术机器人的后起之秀,做临床研究时,总是会用NASA-TLX法来证明与达芬奇手术机器人的性能接近。
为什么选择这个方法?
手术是一个很难量化打分的任务,因为有很多主观因素在,而NASA-TLX就是为主观占比很强的任务量身定制的评价方法。
怎么应用这个评估方法?
也就三步曲。
Why choose this method?
In clinical studies conducted by many emerging surgical robotics companies, the NASA-TLX method is often used to demonstrate performance comparable to that of the Da Vinci surgical robot.
Surgery is a task that is difficult to quantify and score due to its many subjective factors. NASA-TLX, however, is specifically designed as an evaluation method tailored for tasks with strong subjective components.
How is this assessment method applied?
It essentially follows a three-step process.
第一步:根据要评估的对象,把六个维度的权重系数定出来。
这可以做一个调查表,具体见下图的15个问题。注意,不同的评估对象,得出来的结果可不一定相同,下表格记录内容是我以手术机器人的一个示例。
为什么是15个问题?
就是6因素两两PK,那个权重更重,那就是一个排列组合题。
Step 1: Determine the weight coefficients for the six dimensions based on the subject being evaluated.
This can be done using a questionnaire, as shown in the following 15 questions. Note that the results may vary depending on the subject being evaluated. The table below shows an example based on a surgical robot scenario.
Why 15 questions?
This is essentially a pairwise comparison problem involving six factors, where each pair is compared to determine which carries more weight—a classic combinatorial calculation.
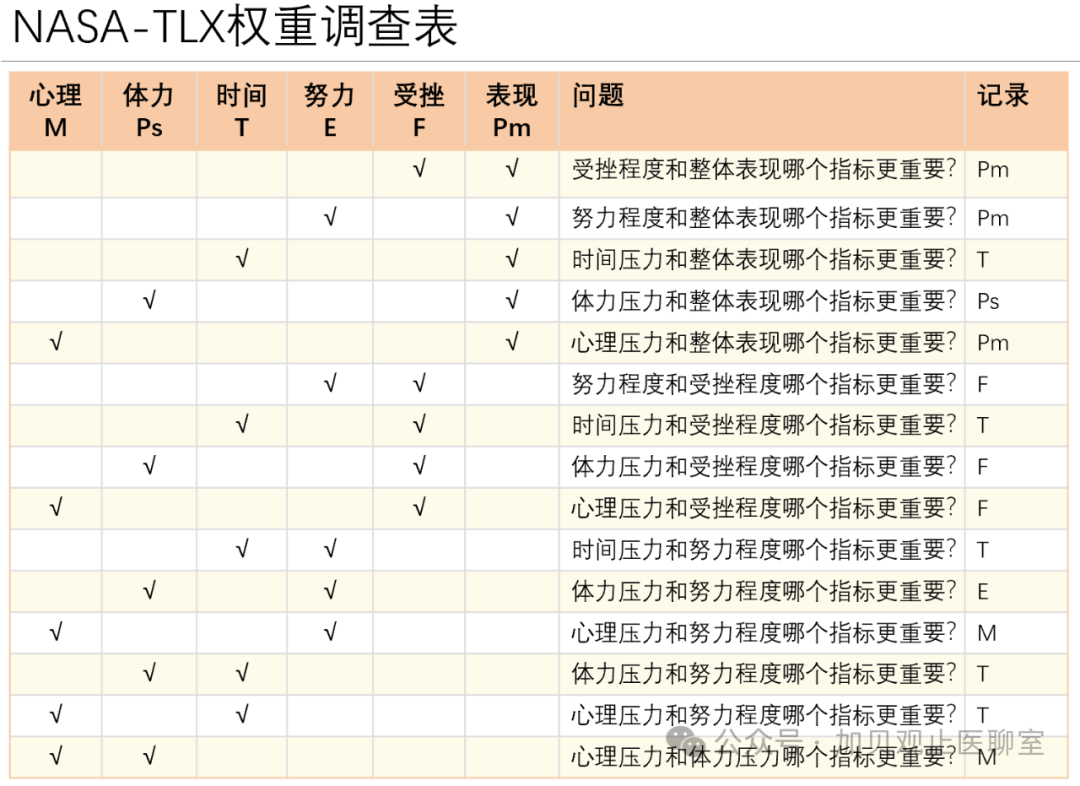
统计记录中各子项出现的频次,除以15,就是各子项的权重了
The weight for each sub-item is determined by counting its frequency in the statistical records and then dividing it by 15.

第二步:根据六个要素设计以下评分表。如果是两个品牌之间的PK,就是两套评分表。可以如此设计调查问卷。回答以下问题,必须明确任务。比如手术机器人的任务是完成手术。那外科医生得通过回顾手术过程的感觉来完成评分。
使用品牌A时,您的心理压力多少分?
使用品牌A时,您的体力压力多少分?
使用品牌A时,您的时间压力多少分?
使用品牌A时,您的努力程度多少分?
使用品牌A时,您的受挫程度多少分?
使用品牌A时,您的整体表现负担多少分
Step 2: Design the Scoring Sheet Based on the Six Dimensions
A scoring sheet should be designed according to the six dimensions. If a comparison between two brands is required, two separate scoring sheets should be prepared. A survey questionnaire can be designed in the following manner.
Important Note: When answering the following questions, the specific task must be clearly defined. For example, if the assessment involves a surgical robot, the task would be "completing a specific surgical procedure." In this case, the surgeon should provide ratings based on their reflections and feelings during the surgical process.
---
When using Brand A, what score would you give for your mental demand?
When using Brand A, what score would you give for your physical demand?
When using Brand A, what score would you give for your temporal demand?
When using Brand A, what score would you give for your effort?
When using Brand A, what score would you give for your frustration?
When using Brand A, what score would you give for your overall performance burden?

把每个问题的单项打分乘以该项的权重系数,就是单项在整个评估的得分。
The score for each individual item in the overall assessment is calculated by multiplying the rating for that question by its corresponding weight coefficient.
第三步:把六项单项分加在一起,就是这个产品在这项任务中的NASA-TLX总分,总任务负荷指数
Step 3: Add the scores of the six individual items together to obtain the NASA-TLX total score for this product on the given task, representing the overall task load index.
03 打分与产品性能的关系
心理压力
我的理解是:因为这是医生做完手术后的回顾性评分,医生同时用了两个品牌(A和B)做手术,如果品牌A经常出故障,医生就会给A品牌的心理负担打分高一些。另一个解读就是:如果同一个术式,比如用多臂的机器人做的多且顺手,而用单孔的做会复杂且不确定影响比较多,那医生的心理负担打分也会高一点。
Psychological Stress
My understanding is that since this is a retrospective rating by doctors after completing surgeries, and the doctors used two brands (A and B) for the procedures, if Brand A frequently malfunctioned, the doctors would assign a higher psychological burden score to Brand A. Another interpretation is: for the same surgical procedure, if a multi-arm robot is used more frequently and feels more intuitive, while a single-port approach is more complex and involves greater uncertainty, the doctors’ psychological burden score would also be higher.
体力压力
我的理解是:如果产品重量太重,或者手感太重,或者姿势别扭,导致医生消耗体力比较大,那体力压力分就会很高。
Physical Stress
My understanding is: if the product is too heavy, feels cumbersome to handle, or forces the doctor into an awkward posture, leading to significant physical exertion, then the physical stress score would be very high.
时间压力
我的理解:很多医院都会把手术时间看得很重,时间是个重要的KPI,如果在手术过程,换器械,或者擦镜子很费时间,那时间压力分就会很高,另外时间越长,麻醉风险也高,并发症的发生概率也相应增加。这个时间压力,在很多术式中都非常关键,个人认为这个指标的权重一般都很高。
Time Pressure
My understanding is: many hospitals place great importance on surgical time, as it is a key KPI. If procedures such as instrument changes or lens cleaning during surgery are time-consuming, then the time pressure score would be very high. Additionally, longer surgical durations increase anesthesia risks and the probability of complications. This time pressure is crucial in many surgical procedures, and personally, I believe the weight of this metric is generally very high.
努力程度
我的理解:直白点,就是费劲程度。外科医生经常开玩笑,用达芬奇手术机器人把手术做好,那算不了什么本事,但用国产机器人把手术做得快又漂亮,那才叫本事。就像开个好车和代步车之间的差别,好的司机是能用自己的能力去让最后结果好看。但费不费劲,只有医生自己知道。
Effort Level
My understanding: To put it plainly, this refers to how much effort is required. Surgeons often joke that performing a surgery well with the da Vinci Surgical Robot is not particularly impressive, but using a domestic robot to complete the surgery quickly and with excellent results—that’s where true skill lies. It’s like the difference between driving a luxury car and an economy car: a skilled driver can use their abilities to achieve a great outcome regardless. But how much effort it truly takes is something only the doctors themselves know.
受挫程度
我的理解:如果手术机器人的手术器械不好使,游离或者夹闭或者缝合都出现了不同程度的失误,又或者破坏了不该破坏的器脏,就是本应该正常水平发挥的能力没有发挥出来,那就是受挫的感受。在初学者身上,这个指标影响更多一点,如果因为机器人上手学习曲线太复杂,这个受挫打分肯定就会高。
Frustration Level
My understanding: If the surgical instruments of the robotic system are not performing well—whether during dissection, clamping, suturing, or if there are varying degrees of errors, or even damage to tissues that should not have been affected—meaning the expected level of performance is not achieved, that leads to a sense of frustration. This metric tends to have a greater impact on beginners. If the learning curve for operating the robot is too steep, the frustration score is likely to be high.
整体表现负担
我的理解:结合以上五点,用户对自己在整个手术中感受到的负担打分。再次提醒,这个分数越高,表示对自己的表现越不满意,注意注意,是整体表现负担。
Overall Performance Burden
My understanding: This score reflects the user’s assessment of the burden they felt throughout the entire surgery, based on the five factors mentioned above. To reiterate, a higher score indicates greater dissatisfaction with their own performance. Please note: this specifically refers to the overall performance burden.
结语
今天把这个弄明白,还是很开心的。在设计产品时,我们很想把产品的主观性能量化,原来写需求的时候,遇到主观项,就不知道如何描述需求,也不知道如何测试。这个方法论能解决很多产品综合主观性能评价的问题。前提是咱们得弄清楚我们的产品要解决用户的任务是什么?
I'm really happy to have figured this out today. When designing products, we always want to quantify their subjective performance. In the past, when writing requirements and encountering subjective aspects, we didn’t know how to describe the needs or how to test them. This methodology can address many issues related to evaluating the comprehensive subjective performance of a product. The key is that we must first clarify what user tasks our product aims to solve.